Know-how de Clipper
 Nesta seção de know-how são de informações mais complexas que são ensinadas.
Nesta seção de know-how são de informações mais complexas que são ensinadas.
Participe também enviando sua colaboração ou debatendo o assunto.
- Login ou registre-se para postar comentários
Anexo:
Arquivos Temporários
Aprenda a confeccionar qualquer tipo de relatório em ambiente de rede, por mais complexo que seja, e de processamento rápido com arquivos temporários em Clipper/xBase/Harbour.
Neste estudo de caso será feito um relátorio de devoluções de produto ao fornecedor de um período, c/ fornecedores em ordem alfabética c/ quebra por fornecedor e por ordem de compra.
Tentarei ser o mais inteligível e objetivo possível, acompanhe todo o estudo e você irá entender. Iremos trabalhar, em nosso caso, com três bases de dados do sistema.
Na estrutura deles (para nosso estudo) teriam alguns campos como:
OrdComp.dbf (OC) Estoque.dbf (ES) Fornec.dbf (FO)
================ ================ ==================
OC________C__8__0 CODPROD__C__5__0 CODFORN___C__2__0
CODPROD___C__5__0 PRODUTO__C__25_0 FORNEC___C__30_0
CODFORN___C__2__0 CODFORN__C__2__0 ...
QTDCOMPRA_N__8__2 QTD______N__6__0
QTDRECEB__N__8__2 VALOR____N__8__2 Index on CODFORN;
QTDDEV____N__8__2 ... TO FOCFOR
VALOR_____N__10_2
DCOMPRA___D__8__0 Index on CODPROD;
DRECEB____D__8__0 TO ESCPROD
DDEV______D__8__0 ...
Index on DTOS(DDEV)+OC;
TO OCDDEV
Em Modelagem de Dados: O OC é um DBF de "vários para um", pois há vários registros (produtos) para uma ordem de compra.
A relação entre OC e ES é de "um para vários", pois em uma ordem de compra há vários produtos.
A relação entre ES e FO é de "vários para um", pois há vários produtos para um só fornecedor.
Atente que as "..." (reticências), em algumas linhas do nosso estudo no programa, indicam que deve haver instruções inerentes ao programa de cada um naquele local.
Vamos ao programa:
USE ORDCOMP ALIAS OC SHARED NEW SET INDEX TO OCDDEV USE ESTOQUE ALIAS ES SHARED NEW SET INDEX TO ESCPROD USE FORNEC ALIAS FO SHARED NEW SET INDEX TO FOCFOR
Vamos colher dados do usuário p/ o nosso relatório:
DATAI := DATAF := CTOD("")
@ 10,10 SAY "Data inicial:" GET DATAI
@ 11,10 SAY "Data final..:" GET DATAF VALID DATAF >= DATAI
READ
IF LASTKEY() = 27
// ...
RETURN
ENDIF
Vamos dar um SOFT SEEK para reduzir drasticamente o tempo de nosso relatório.
OC->( DBSEEK( DTOS(DATAI), .T.) )
IF OC->DDEV > DATAF
ALERT("Não houve devoluções a nenhum fornecedor nesse período!")
// ...
RETURN
ENDIF
Precisaremos de um arquivo temporário para as informações que queremos armazenar e mostrar.
Veja que, trabalhando em ambiente de rede não podemos dar um nome fixo como "temp.dbf" por exemplo, pois se dois ou mais usuários pedirem este relatório ao mesmo tempo o DBCREATE() não criará um arquivo que já existe e o programa irá, no mínimo (dependendo de cada caso), duplicar as informações no temporário e bagunçar todo o relatório. Teremos, então, que criar um nome mutante para este temporário... observe:
TEMP := "TEMP"+SUBSTR( TIME(), 4, 2 )+SUBSTR( TIME(), 7, 2 ) TEMPNTX := "NTX" +SUBSTR( TIME(), 4, 2 )+SUBSTR( TIME(), 7, 2 )
As variáveis TEMP e TEMPNTX guardam o nome do temporário e do seu NTX. Depois temos a "&" e/ou os "()", para estrair esses nomes, dependendo da sintaxe do comando/função.
*** Criação do temporário ***
aDBF := {}
aADD( aDBF, {"OC", "C", 8, 0} )
aADD( aDBF, {"CODPROD", "C", 5, 0} )
aADD( aDBF, {"PRODUTO", "C", 25, 0} )
aADD( aDBF, {"CODFORN", "C", 2, 0} )
aADD( aDBF, {"FORNEC", "C", 30, 0} )
aADD( aDBF, {"QTDRECEB","N", 8, 2} )
aADD( aDBF, {"QTDDEV", "N", 8, 2} )
aADD( aDBF, {"VALOR", "N", 10, 2} )
aADD( aDBF, {"DCOMPRA", "D", 8, 0} )
aADD( aDBF, {"DRECEB", "D", 8, 0} )
aADD( aDBF, {"DDEV", "D", 8, 0} )
DBCREATE( &TEMP, aDBF )
Está criado o nosso temporário...
Abriremos o nosso arquivo desta forma:
USE (TEMP) ALIAS TMP EXCLUSIVE NEW INDEX ON FORNEC+OC+PRODUTO TO (TEMPNTX)
Vamos preencher as informações necessárias em nosso "temp" agora...
DO WHILE DDEV <= DATAF
Vamos mover o ponteiro de registro das outras áreas p/ que todas entrem de acordo.
ES->( DBSEEK(OC->CODPROD) ) FO->( DBSEEK(OC->CODFORN) )
Agora preencher as informações do temporário...
TMP->OC := OC->OC TMP->CODPROD := OC->CODPROD TMP->PRODUTO := ES->PRODUTO TMP->CODFORN := OC->CODFORN TMP->FORNEC := FO->FORNEC TMP->QTDRECEB := OC->QTDRECEB TMP->QTDDEV := OC->QTDDEV TMP->VALOR := OC->QTDCOMPRA/OC->VALOR TMP->DCOMPRA := OC->DCOMPRA TMP->DRECEB := OC->DRECEB TMP->DDEV := OC->DDEV OC->( DBSKIP() ) ENDDO TMP->( DBCOMMIT() )
Agora vamos ao relatório propriamente dito!
TMP->( DBGOTOP() ) cFOR := TMP->FORNEC cOC := TMP->OC LL := 100 LP := 60
Substitua pela variável do número de linhas/página da impressora atualmente configurada, caso seu sistema possua configuração múltipla de impressora.
DO WHILE !TMP->( EOF() )
IF LL >= LP //Quebra de página
LL := 0
...
@ LL++,00 SAY REPLI("-",80)
@ LL++,00 SAY "Fornecedor Código"
@ LL++,00 SAY " Ord. Compra Data de Compra, Receb. e Devolucao"
@ LL++,00 SAY " Produto Cód. Qtd.Rec. Qtd.Dev Dev.% Dev.$"
@ LL++,00 SAY REPLI("-",80)
@ LL++,00 SAY cFOR+" "+TMP->CODFORN
@ LL++,05 SAY cOC+" "+DTOC(TMP->DCOMPRA)+", "+DTOC(TMP->DRECEB)+", "+DTOC(TMP->DDEV)
@ LL,10 SAY TMP->PRODUTO
@ LL,36 SAY TMP->CODPROD
@ LL,42 SAY TMP->QTDRECEB
@ LL,51 SAY TMP->QTDDEV
DEVp := (TMP->QTDDEV*100)/QTDREC
DEVv := TMP->QTDDEV*TMP->VALOR
@ LL,60 SAY DEVp PICTURE "@R 999.99%"
@ LL++,68 SAY DEVv PICTURE "99999.99"
TMP->( DBSKIP() )
ENDIF
cFOR := TMP->FORNEC
cOC := TMP->OC
IF cFOR # TMP->FORNEC
cFOR := TMP->FORNEC
cOC := TMP->OC
@ LL++,00 SAY cFOR+" "+TMP->CODFORN
@ LL++,05 SAY cOC+" "+DTOC(TMP->DCOMPRA)+", "+DTOC(TMP->DRECEB)+", "+DTOC(TMP->DDEV)
ENDIF
IF cOC # TMP->OC
cOC := TMP->OC
@ LL++,05 SAY cOC+" "+DTOC(TMP->DCOMPRA)+", "+DTOC(TMP->DRECEB)+", "+DTOC(TMP->DDEV)
ENDIF
@ LL,10 SAY TMP->PRODUTO
@ LL,36 SAY TMP->CODPROD
@ LL,42 SAY TMP->QTDRECEB
@ LL,51 SAY TMP->QTDDEV
DEVp := (TMP->QTDDEV*100)/QTDREC
DEVv := TMP->QTDDEV*TMP->VALOR
@ LL,60 SAY DEVp PICTURE "@R 999.99%"
@ LL++,68 SAY DEVv PICTURE "99999.99"
TMP->( DBSKIP() )
ENDDO
Observe que o arquivo temporário deverá ser apagado no final do programa, caso contrário com o tempo a capacidade de registros de arquivos da FAT (tabela de alocação de arquivos) estourará e nenhum outro arquivo poderá ser criado neste diretório e destarte ocasionará um erro fatal.
TMP->( DBCLOSEAREA() ) //Deve-se fechar o arquivo antes de apagá-lo TEMP += ".DBF" TEMPNTX += ".NTX" FERASE( TEMP ) FERASE( TEMPNTX ) RETURN *------------------------------
Bem, aí está o estudo completo! Espero que tenha gostado. Vamos debater o assunto? Poste seu comentário.
- Login ou registre-se para postar comentários
Automatização da reestrutura dos DBF
Como atualizar a estrutura dos banco de dados dos sistemas Clipper.
(c) 2.000 Mega Software & Micro Informatica Ltda
Desenvolvemos para nosso sistema um método que automaticamente verifica se os DBFs tiveram alteração de estrutura e ajusta os arquivos para a nova estrutura.
O conceito é o seguinte :
1. Você define todas as estruturas de todos os arquivos os quais seu sistema irá manipular.
2. Você cria uma função que retorne essa estrutura. No nosso caso, GetStru()
3. Ao subir o sistema, você pega cada estrutura dos arquivos - com dbstruct() por exemplo - e a estrutura definida internamente no seu sistema.
4. Você compara as duas estruturas - no nosso caso, com CmpStru()
5. Se forem iguais, está tudo OK e você retorna.
6. Se diferentes - qualquer diferença que não alteração de tipo de campo (pois neste caso poderá ser gerado um erro com os comandos utilizados nesta função ) , você deverá :
6.1 Gravar um arquivo novo com os dados atuais.
6.2 Comparar os dados gravados com os atuais.
6.3 Apagar o atual e criar o novo com a nova estrutura.
6.4 Appendar os dados do arquivo gravado
6.5 Comparar os dados appendados com os gravados originalmente.
7. Fim do Processo.
Algumas proteções são colocadas :
1. Ao começar uma revisão , o sistema cria o Arquivo VERSION.DAT . Se algum outro terminal tentar subir o programa e, se encontrar este arquivo, significa que :
1.1 Algum terminal está fazendo revisão e eu não posso subir agora.
1.2 Alguém (talvez eu mesmo) estava fazendo revisão de sistema e o sistema caiu , ou a máquina caiu, parou a força, etc...
Em qualquer caso, deve haver duas opções, Você entrar e continua Revisão ou Desiste de subir no programa para subir mais tarde.
2. Conforme começar a revisão, todos os arquivos de índice associados ao arquivo serão apagados o sistema deve ter mecanismos de criá-los automaticamente sempre que for abrir um arquivo.
3. Se sistema caiu fazendo revisão, através do estado do arquivo de back-up gravado, ele saberá em que ponto parou e o que fazer para não perder dados.
4. Uma variável global, associada preferencialmente a algum campo de um arquivo de configuração do sistema, indicará se pode ou não haver checagem ou não de integridade de DBFs e NTX.
Envio arquivo anexo com as funções descritas neste documento. Espero que possa ser útil a alguém.
Automatize a reestruturação dos DBF!
- Login ou registre-se para postar comentários
Bug do Milênio
O ano 2000 chegou!!! Você está preparado???
ATENÇÃO: Todas as datas com ano 00 gravadas antes do SET EPOCH serão tratadas como 1900! Ou seja, após a implantação deste comando, você poderá ter datas com ano 00 que signifiquem 1900 e 2000 no mesmo DBF!!! Descobri isto a duas semanas no meu trabalho, sem embargo, só tive tempo p/ publicar isto agora devido à atribulação de tempo com provas finais na universidade. Não obstante, elaborei uma função de uso genérico que lê todos os DBFs do diretório corrente e lê todos os campos do tipo data de cada DBF e então transforma as datas interpretadas como 1900 para 2000!!! Quer mais moleza que essa??? Batizei a função de FIXDATE, ela está em anexo. Inclui o fonte p/ você testar c/ o debug se quiser comprovar!!! Qualquer dúvida ou comentário poste-a no fórum, ok?!
Muito bem, então você tem campos tipo caracter para armazenar informações de datas, como por exemplo apenas o ano e o mês da data <AAMM> ou <MMAA>. Bem, você deu azar... Calma! Apenas terá um pouco mais de trabalho... far-se-á necessário acrescentar mais 2 (dois) digitos ao tamanho destes campos na base de dados e no programa para receber o século, mudando todo o código para manipular estes dados no seu sistema para isso. Não se desespere! Primeiramente, copie seu sistema para outro diretório para este trabalho, pois pode demorar e você precisar dar algum tipo de manutenção urgente. Para ajudar-lhe, colocarei a disposição o programa Y2K.PRG que também está em anexo, ele detectará todas as bases de dados que contiverem este campo, altere estas bases de dados acrescentando mais 2 caracteres ao seu tamanho e depois rode o programa de novo, ele irá acrescentar os dígitos "19" na frente no ano. Esta minha função ajudará apenas na preparação dos bancos de dados, no programa é com você!!! Este trabalho merece muita atenciosidade, então: Boa concentração e mãos à obra!!!
Se seu sistema possui apenas campos do tipo date para armazenar dados do tipo data será muito simples. O clipper possui um comando chamado Set Epoch to <YYYY>, onde YYYY é o ano base. Por exemplo, Set Epoch to 1980 trataria os campos date que tivesse um ano menor que 80 como do século seguinte e um ano maior que 80 como do mesmo século, i.e. de dd/mm/00 a dd/mm/79 seriam tratadas do século XXI (2000) e as datas de dd/mm/80 a dd/mm/99 do século XX (1980). Neste caso, sabendo que sua empresa está no mercado desde 1985 e não possui nenhum registro antes deste ano, você colocaria Set Epoch to 1985 no programa principal do seu sistema.
SET EPOCH TO 1980
| Publique seu know-how aqui também, registre-se e inclua uma subpágina ou acrescente seus comentários. |
- Login ou registre-se para postar comentários
Clipper no Windows 64Bits

Clipper no Windows 64bits não roda porque ele é um compilador que gera arquivos de 16bits. Pode não ser um problema instalar uma plataforma de 32bits no seu cliente, principalmente se for uma máquina dedicada a rodar o seu sistema, mas pode ser que você não queira instalar na sua casa uma plataforma de 32bits só por causa do Clipper. Afinal, o Windows de 32Bits só consegue gerenciar até 3GB de memória RAM. Se você tiver 4GB ou mais de memória e você consultar as Propriedades do Sistema, verá 2,99GB de RAM. Não é problema de memória! Então, caso você tenha 4GB ou mais, vai ter que instalar o Windows de 64Bits.
Um sistema de 64 bits quer dizer que ele processa 64bits de uma só vez, ou seja, processa mais bits ao mesmo tempo do que um de 32bits ou 16bits. Portanto, processa mais rápido! Faz cálculos maiores também!
Um sistema operacional de 64 bits roda 32 bits, mas não roda 16 bits, enquanto que, um sistema de 32 bits roda 16 bits, mas não roda 64 bits.
Enfim, não fugiremos do tema, se quiser saber mais sobre 64 bits, consulte esta página da própria Microsoft: http://windows.microsoft.com/pt-BR/windows7/products/features/64-bit-support
CLIPPER NO WINDOWS 64bits
Existem alguns emuladores de "máquinas virtuais" onde você instala qualquer Sistema Operacional dentro dele. Vamos ensinar aqui como você vai fazer isso com o VIRTUAL BOX.
![]() Baixe o Virtual Box (Clique no link abaixo)
Baixe o Virtual Box (Clique no link abaixo)
- VirtualBox for Windows hosts
Instale o aplicativo com as opções padrões. Você poderá instalar qualquer sistema operacional dentro do Virtual Box.
- VirtualBox Extension Pack
Recomendo instalar logo o extension pack também.
Você terá que instalar o sistema operacional de 32 bits que roda o Clipper. Eu escolhi o Windows XP.
O Virtual Box separa um determinado espaço do seu HD para transformá-lo num HD virtual onde você vai instalar e rodar o sistema operacional que você desejar dentro de uma janela como se fosse um aplicativo comum no seu computador.
Você vai precisar do disco de instalação do Windows XP ou qualquer outra versão do Windows em 32bits para instalar ele dentro do Virtual Box como se fosse instalar ele normalmente num Hard Disk (HD) formatado.
O problema é que quando estiver pronto, suas pastas do computador não irão aparecer! Pois, naquele "disco virtual" só tem o Windows que você acabou de instalar! Para resolver isso, faça o seguinte:
Vá na barra de menu DISPOSITIVOS e clique em INSTALAR ADICIONAIS PARA CONVIDADO.
Depois de INSTALAR ADICIONAIS PARA CONVIDADO, vá em PASTAS COMPARTILHADAS e clique no ícone de uma pasta com sinal de + (mais), então vai aparecer uma janela. Onde tem "caminho da pasta" nesta janela, selecione "outro", então selecione "computador" e unidade raíz "Disco Local (C:)". Marque "Montar automaticamente" e "Tornar Permanente". Confirme no botão "OK".
Você agora precisa reiniciar a máquina virtual para que as pastas compartilhadas apareçam. Na barra de menu, clique em "Máquina" e então "Reiniciar".
O Virtual Box vai atribuir uma letra de unidade de drive ao seu compartilhamento, por exemplo, vai dizer que "E:" é seu "C:".
Daí, é só você ir em MENU INICIAR > PAINEL DE CONTROLE > DESEMPENHO E MANUTENÇÃO > SISTEMA, então selecione a aba AVANÇADO e clique em "Variáveis de ambiente" para configurar a instalação do Clipper, com as variáveis CLIPPER, INCLUDE, LIB, OBJ e não esqueça de colocar o caminho da pasta BIN do Clipper na variável PATH também!
VOILÀ! Agora você pode executar o Clipper dentro do Windows XP dentro do Virtual Box!

Virtual Machine na BIOS
Se a dica acima não funcionar é porque você precisa habilitar a máquina virtual na BIOS. Sim, ainda tem isso.
O Intel Virtualization, Intel -VT, AMD-V, VT-D ou Virtualization Technology é um recurso presente nos processadores que podem ser ativados no BIOS/UEFI quando a CPU dá suporte.
Ative Esse Recurso – Melhor Desempenho E Segurança!
Programa em Clipper com 32 ou 64bits
Para início de conversa, Clipper é um compilador da Linguagem xBase, Clipper não é o nome da linguagem de programação. Acontece que o nome desse compilador é tão popular que chamamos "programar em Clipper" mesmo assim até hoje. Semelhantemente chamamos "palha de aço" de simplesmente Bombril e "hastes flexíveis com pontas de algodão" simplesmente de Cotonetes.
Ciente disso revolvemos o impasse. Basta achar um novo compilador xBase 100% compatível com o Clipper que faça o trabalho.
Afinal, seria muito melhor se a gente pudesse compilar o sistema logo em 32 ou 64 bits, não é mesmo?
Sim existe! Temos o Projeto Harbour, xHarbour e o HMG que são exemplos de compiladores 100% compatíveis com o Clipper que compilam em 32bits por padrão, mas podem compilar em 64bits também se configurado para isso.
A gente sempre arruma um jeitinho para rodar o Clipper! VIVA O CLIPPER!
- Login ou registre-se para postar comentários
Consistência dos índices
Consistência dos Arquivos de índice
Verifique se as quebras constantes dos arquivos de índice do Clipper ou [x]Harbour são "furos" no programa!
Integridade do Banco de Dados
- Restrição de domínio
- Restrição de chave primária
- Restrição de chaves externas
Restrição de domínio
Significa restringir o conteúdo dos campos a valores válidos. Domínio é um conjunto de valores possíveis. Por exemplo, para entrar com um código de cliente em uma fatura, você precisa verificar se aquele código existe na tabela de clientes.
Restrição de chave primária
Precisa apresentar 2 propriedades: Exclusividade e minimalidade.
Exclusividade: significa que se x (uma ou uma combinação de campos) é a chave primária, não poderá haver, em hipótese alguma, mais de um registro com o mesmo valor de x.
Minimalidade: é um pouco mais difícil de explicar. Significa que nada que viole sua exclusividade pode ser descontado da classe primária. Por exemplo, a combinação de campos (numero_peca, nome_peca) pode ser uma chave exclusiva. Dois registros não poderão ter os mesmos valores em ambos os campos, mas não é o 'mínimo'. Você pode retirar o nome da peça da chave e ela ainda será exclusiva. O número da peça é o mínimo necessário para identificar o registro.
Observe que você só pode selecionar uma chave primária após um amplo estudo dos dados.
* Restrição de chaves externas
Você define as relações entre tabelas usando o mesmo campo em duas tabelas diferentes.
O 'pai' estabelece a relação baseado em suas chaves primárias. Na relação Cliente->Fatura, por exemplo, a tabela de clientes é o pai, e a relação está baseada em Num_cliente, chave primária da tabela Clientes. Esta chave também existe na tabela filho e, nesta tabela, ela é chamada 'chave externa'. Ela é uma chave primária de uma tabela, mas não desta. Ela é um campo, ou uma combinação de campos, cujos valores precisam corresponder a uma chave primária definida em outra tabela.
Ao incluir registros em uma tabela, você precisa assegurar que as chaves externas correspondam a uma chave primária definida no banco de dados-pai. Por exemplo, ao incluir uma fatura no sistema, você deve garantir que o campo Num_cliente na tabela Faturas corresponda a um cliente inserido na tabela Clientes. Para impor esta 'integridade referencial', é preciso determinar p/ cada relação, o que fazer quando uma chave primária for modificada ou seu registro for eliminado. Existem 3 métodos de ação:
RESTRINGIR: A chave primária eliminada ou atualizada é desautorizada se existirem chaves externas com esse valor.
EFEITO CASCATA: Eliminar ou atualizar em efeito CASCATA as chaves externas. Por exemplo, se eliminarmos o cliente 10, todas as faturas pertencentes ao cliente 10 serão eliminadas da tabela Faturas. O mesmo se aplica às atualizações. Todas as chaves serão também atualizadas.
ANULAR: As chaves externas com o valor da chave primária eliminada ou atualizada serão definidas com um valor nulo (no clipper, corresponde a um valor predefinido como nulo/desconhecido, pois não existe nulo no sentido da palavra).
Addendum 28/06/2002:
Foi constatado que a corrupção nos arquivos de índices do RDD DBFNTX pode ser reduzida quando se abre todos os índices do arquivo DBF sempre em uma mesma ordem e só depois você determina o índice ativo com DBSETORDER(), por exemplo. Se você tem muitos problemas com corrupção dos índices .NTX, faça um teste e dê o seu depoimento, ok?! Aliás, sempre abra todos os índices de cada banco de dados junto senão eles ficarão desatualizados e não servirão.
Não seria por isso que o RDD DBFCDX é mais consistente?! Os índices deste RDD podem ser criados em um único arquivo .CDX, ou seja, vários índices (chamados de "bolsa") criados em um único arquivo de índice e toda vez que você abre este arquívo, todos os índices estarão abertos e disponíveis sempre na mesma ordem...
O RDD Comix mais o ClipMore (extensão .CDX) é uma dupla muito bem falada pela maior robustez e velocidade dos seus arquivos de índices que os índices RDD DBFCDX naturais do Clipper.
O RDD SixDrive (extensão .NSX) é clamado o melhor que existe por várias pessoas, os arquivos de índice são menores que os .CDX e, também, são mais rápidos ainda, sem embargo, há depoimentos que seus arquivos se corrompem muito facilmente. Seria viável?!
------------------
Fonte: Clipper 5.2 - Rick Spence, Makron Books, p.244-249.
- Login ou registre-se para postar comentários
Migração do Clipper 5.01 para 5.2
ERRO NA ATUALIZAÇÃO DO CLIPPER PARA VERSÃO 5.2

Saiba como resolver o erro na atualização do Clipper versão 5.2e "DBCMD/1011 Alias already in use" num método prático de uma vez só sem precisar quebrar a cabeça com o código do seu sistema.
Erro que aparece no Clipper 5.2e ao abrir banco de dados: "DBCMD/1011 Alias already in use".
Em um sistema Clipper quando um programa abrir um banco de dados para trabalhar deve fechar depois no final, até pra não deixar o tráfego da rede lenta. Todavia, na prática, nem sempre isso acontece. Muitas vezes o programa abre vários bancos de dados e depois não fecha. Daí a versão do Clipper 5.2e foi bem rigoroso e pegou no pé de quem fazia isso dando erro se tentasse abrir um banco de dados que já estava aberto.
É, amigo. Na versão anterior 5.01 não havia isso... você abria o mesmo arquivo em vários momentos do seu sistema e isso nunca aconteceu... e agora? Teremos que verificar se o arquivo já está aberto toda vez que for abrir um arquivo??? Substituir por uma função??? De qualquer forma, ter que alterar todo o sistema será muito trabalhoso... e é por isso que você está lendo isso! Você quer outra solução, uma saída elegante e profissional para este caso... E VOCÊ TERÁ!!!
Sabemos que todo comando em Clipper é transformado em uma função (Nossa sorte! USE é um comando) e todos os comandos do Clipper estão no arquivo de cabeçalho \include\STD.ch.
Calma! Não é só isso! As alterações que você fizer no arquivo STD.ch não serão consideradas pelo Clipper...! (hã?!)
 O QUE PRECISAMOS FAZER
O QUE PRECISAMOS FAZER
Baixe o arquivo anexo, migra52.zip.
Precisamos fazer uma cópia do arquivo STD.ch para outro arquivo, STD_BAK.ch, por exemplo.
Agora busque a palavra DBUSE dentro do arquivo STD_BAK.ch; na linha que traduz o comando USE para a função DBUSEAREA, troque o nome DBUSEAREA para o nome de nossa função: BWNUSE. Salve o arquivo (Veja o arquivo STD_BAK.ch dentro do Migra52.zip baixado)
Compile o arquivo USEFILE.prg e o insira na sua biblioteca de funções (preferivelmente) ou linkedite o objeto deste arquivo no seu sistema. Neste arquivo está minha função para abrir os arquivos sem problema algum. O arquivo USEFILE.prg está incluido no arquivo Migra52.zip.
Ao compilar os programas do sistema insira o parâmetro /U com o nome do novo arquivo de cabeçalho que o Clipper irá usar colado nesse parâmetro, STD_BAK.ch. Exemplo:
Clipper <programa> /USTD_BAK.ch
Ou no seu arquivo do Rmake (.rmk):
// Determine if DEBUGging is enabled #ifdef DEBUG CompOptions := /b /m /n #else CompOptions := /m /n #end .prg.obj: clipper $< $(CompOptions) /USTD_BWN.ch PRGs.obj : PRGs.obj
Com isso você dribla este problema de versão que o impedia de rodar o seu sistema em Clipper 5.2!!! 
Talvez ocorra alguns problemas na função que você desenvolveu com a classe TBROWSE, principalmente se você andou passando argumentos errados para ela ao longo do seu sistema...! DICA: Veja os exemplos da CA em \SOURCE\TBROW\ e reescreva sua função de acordo com eles se for o caso.
- Login ou registre-se para postar comentários
PCODE do Clipper
PCODE do Clipper
Pcode é uma abreviação de pseudo código e serve para intermediar o código de máquina com a linguagem Clipper. Cada pcode é substituído por um código de máquina.
Se você está interessado em saber sobre pcode é porque provavelmente perdeu os fontes do seu sistema e precisaria fazer alguma alteração módica no programa, tipo alterar o valor de uma variável ou parâmetro de uma função, tipo o SET EPOCH TO 1910 para SET EPOCH TO 1980 (Caso concreto que me levou a estudar esse assunto). Se você dominar o PCODE pode até construir um descompilador no próprio Clipper, assim como fez Wagner Nunes da Silva com o seu DCLIP.
Se você pegar o WDASM que é um "disassembler" (descompilador) que funciona com programas em 16 bits como os aplicativos gerados pelo Clipper, você poderá abrir o aplicativo *.EXE e ver a tradução do código de máquina em Assembly.
Assembly é uma das linguagens de baixo nível mais próximas do código de máquina que existe senão a mais próxima. Mas, daí você teria que estudar Assembly para modificar o seu *.EXE.
No caso, o SET EPOCH TO 1910 estaria aqui:

Observe que o código de máquina fica do lado esquerdo (13 09 00 3B 05 00 3B 76 07) enquanto que o Assembly correspondente fica do lado direito. Mesmo tendo lido um pouco a respeito desta linguagem, esse pedaço de código parece não representar nada para mim, nunca que saberia que esse Assembly aí seria o SET EPOCH TO 1910.
Aliás, se você escrever um código em Assembly, tipo o clássico "Olá, mundo!" e abrir depois com o debug do MS-DOS ou o WDASM mesmo, verá que o código fica diferente. Veja:
.model small
.stack
.data
message db "Hello world, I'm learning Assembly !!!", "$"
.code
main proc
mov ax,seg message
mov ds,ax
mov ah,09
lea dx,message
int 21h
mov ax,4c00h
int 21h
main endp
end main
Esse programa compilado como first.exe ao ser visto pelo MS-DOS com o comando "debug first.exe", mostra a tela do debug, daí tecle "u", então verá o programa do jeito parecido como vê no WDASM com o código de máquina do lado esquerdo e o Assembly do lado direito, desse jeito:
0F77:0000 B8790F MOV AX,0F79 0F77:0003 8ED8 MOV DS,AX 0F77:0005 B409 MOV AH,09
Veja o quanto mudou! Não dá pra entender isso assim tão fácil pra mexer direto no *.EXE. Portanto, é melhor partir pro PCODE mesmo!
Observe que o pcode é um código de máquina em hexadecimal.
Agora veja a tela do Valkyrie daquele mesmo pedaço do programa em pcode:
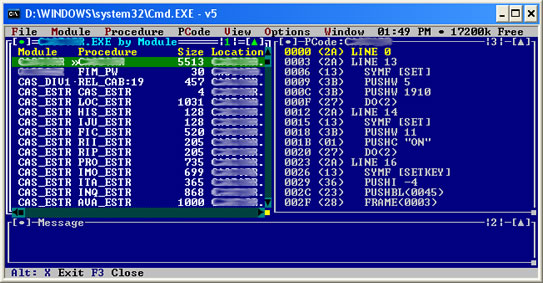
Saiba que o pcode do SYMF é 13; PUSHW é 3B; SET(5, 1910) é igual a SET EPOCH TO 1910.
No nosso exemplo, o "SYMF [SET]" equivale a "13 09 00". Nem sempre o 13 09 00 equivale a SYMF [SET], mas isto é outra estória mais complicada, pois o "09 00" é uma word que depende da Tabela de Símbolos do Clipper (CA-Clipper´s Symbol Table) que pode ser diferente em cada compilação de um *.EXE. O nome dos programas, funções criadas nele, variáveis e seus tipos são criados nesta tabela. Ela contém 16 bytes por símbolo. Todo código no arquivo .OBJ se refere a esta Tabela de Símbolos que pode crescer até 64Kb.
Para mexer diretamente no *.EXE precisamos de um editor Hexadecimal para trabalhar. No caso, sugerimos o Hex Editor Neo que é o Freeware que utilizamos.
Vejamos como fica a tela no Hex Editor:

A coluna da direita na tela acima é arquivo *.EXE, como veríamos na tela, representados por caracteres ASCII. Como trabalhamos com código de máquina em Hexadecimal, precisamos utilizar o código hexadecimal do caracter da tabela ASCII.
Os parâmetros de PUSHW são valores do tipo numérico inteiro binário de 16 bits (word) que podemos obter com a função nativa do Clipper chamada I2BIN(). Esta função sempre retornará 2 bytes porque cada um equivale a apenas 8 bits (8 bits [byte] + 8 bits [byte] = 16 bits [word]). Depois você tem que converter esses 2 caracteres em código hexadecimal. Podemos obter o código decimal do caracter com ASC() e depois convertê-lo em hexadecimal por meio de fórmulas matemáticas.
Como o databus do 8086 (MS-DOS) é 16-bits, ele pode mover e armazenar 16-bits (1 word = 2 bytes) ao mesmo tempo. Se o processador armazena uma "word" (16-bits) ela o faz em ordem reversa na memória, por exemplo: 1234h (word) ---> memory 34h (byte) 12h (byte). Então, se a memória parece como 34h 12h e você pega uma word da memória, você pegará o valor 1234h (Note que usamos o "h" depois do número para indicar que é hexadecimal). Se apenas pegar um byte da word 1234h, o primeiro byte será 34h.
Na pesquisa (Find) ilustrada na figura acima, sabemos que sempre terá 3B 05 00 que é o equivalente a PUSHW 5 ( do SET(5,X) ), pois o hexadecimal é um sistema numérico que vai de 0 a F equivalente a 0 a 15 em decimal (base 16), portanto o 5, como é pequeno (menor que 15) sabemos de cara sem fazer nenhum cálculo que é 5 mesmo, ou seja 5 é 05h. Como devem ser 2 bytes, seriam 00h 05h, mas como acabamos de aprender, devido à segmentação de memória do MS-DOS, ficará como como 05h 00h.
Já estamos vendo na figura que 1910 equivale a 76h 07h. Precisamos alterar para 1980, então vejamos:
ANO := I2BIN(1980) // converte o número em uma palavra (word, 16 bits). ? LEFT(ANO, 1), "=", ASC( LEFT(ANO, 1) ) // ? = 188 decimal ? RIGHT(ANO, 1), "=", ASC( RIGHT(ANO, 1) ) // • = 7 decimal
Observe que não vamos simplesmente converter o número 1910 em hexadecimal. Precisamos converter o número em uma palavra de 16 bits (word) primeiro. Aí sim, converteremos cada caracter (byte) em seu valor hexadecimal. No exemplo acima obtivemos valores decimais 188 e 7 que teremos que converter em hexadecimal. Vemos de cara que 7 é 7h mesmo, mas 188 é maior que 15, então vamos aprender como é que transformamos ele em hexadecimal seguindo a inteligência do exemplo abaixo.
Sistema Hexadecimal
Este é um sistema numérico posicional bastante usado em informática, especialmente em programação Assembly. Neste sistema dispomos de 16 símbolos conforme mostra a tabela abaixo:
|
Símbolo |
Valor absoluto |
|---|---|
|
0 |
0 |
|
1 |
1 |
|
2 |
2 |
|
3 |
3 |
|
4 |
4 |
|
5 |
5 |
|
6 |
6 |
|
7 |
7 |
|
8 |
8 |
|
9 |
9 |
|
A |
10 |
|
B |
11 |
|
C |
12 |
|
D |
13 |
|
E |
14 |
|
F |
15 |
Convertendo de Decimal para Hexadecimal
Sabendo-se que o sistema hexadecimal dispõe de 16 símbolos (você conta com o zero), concluímos que sua base é 16. Podemos converter qualquer número decimal em hexadecimal dividindo-o sucessivamente por 16, que é a base do sistema numérico desejado, até seu quociente ser 0. Vejamos o exemplo da conversão do número decimal 23870 para hexadecimal:
|
Dividendo |
Divisor |
Quociente |
Resto |
|---|---|---|---|
|
23870 |
16 |
1491 |
14 |
|
1491 |
16 |
93 |
3 |
|
93 |
16 |
5 |
13 |
|
5 |
16 |
0 |
5 |
Tomando-se os restos na ordem inversa e seus respectivos símbolos, temos:
|
Resto |
5 |
13 |
3 |
14 |
|
Símbolo |
5 |
D |
3 |
E |
Assim concluímos que o número decimal 23870 convertido para hexadecimal é: 5D3E.
Seguindo o mesmo entendimento, descobrimos que 188 é BCh ou simplesmente pegue a calculadora científica do Windows, marque "Dec" e digite 188, depois marque "Hex". Então, descobrimos que o valor 1980 passado pelo SET é equivalente a: BCh 07h. Da mesma forma teríamos descoberto que 1910 é: 76h 07h.
O Clipper não tem uma função que converta decimal para hexadecimal, mas que tal fazermos uma? Vamos traduzir essa matemática toda em um programa bem simples?
Vamos chamá-la de DEC2HEX(). Vejamos:
* AUTOR: ANDERSON CARDOSO SILVA
* www.linguagemclipper.com.br
CLS
? 23870, " EM DECIMAL É: ", DEC2HEX(23870) // RETORNA: 5D3E
? 188, " EM DECIMAL É: ", DEC2HEX(188) // RETORNA: BC
QUIT
FUNCTION DEC2HEX(nDEC)
cHEX :=""
IF VALTYPE(nDEC)="N"
aBASE16 := {"0","1","2","3","4","5","6","7","8","9",;
"A","B","C","D","E","F"}
aHEX := {}
nDIVIDENDO := nDEC
nQUOCIENTE := 1 // só pra entrar no DO WHILE
DO WHILE nQUOCIENTE # 0
nQUOCIENTE := INT(nDIVIDENDO/16)
nRESTO := nDIVIDENDO % 16
nRESTO++ // SOMA 1 PORQUE aBASE16 COMEÇA COM "0" E NÃO "1"
cHEX:= aBASE16[nRESTO]
aADD(aHEX, cHEX)
nDIVIDENDO := nQUOCIENTE
ENDDO
ENDIF
cHEX := ""
FOR X=LEN(aHEX) TO 1 STEP -1
cHEX += aHEX[X]
NEXT
RETURN cHEX
Sabendo que 1910 é "76h 07h" constatamos que o bloco marcado no Hex Editor é realmente o que pretendemos mexer, pois temos "3B 05 00 3B 76 07" que equivale ao (5, 1910) da função SET. Então, agora basta mudar o "76 07" por "BC 07", ou simplesmente o 76h pelo BCh e voilà!
Runtime error R6003 / Error Divide by 0
Agora que você já está craque, caso você tenha perdido os fontes de um determinado sistema que tenha esse erro do "divide by 0", basta procurar a seguinte sequência no seu programa com o Hex Editor:
B8 52 17 8B CA 33 D2 F7 F1
Então, substitua os últimos bytes F7 F1 com 90 90.
=> Em nossa página de downloads tem um patch que faz isso automaticamente pra você, chama-se div0. 
ATENÇÃO: Mexer diretamente no código de máquina do seu sistema pode fazer com que ele não funcione mais, portanto em qualquer caso FAÇA BACKUP PRIMEIRO antes de tentar isso.
____________________________
Fontes consultadas:
http://www.inf.unisinos.br/~barbosa/paradigmas/consipa3/61/s16/arquivos/curiosidades.html (Pcode)
http://www.genesys.4mg.com/pcode.htm (Pcode)
http://www.xs4all.nl/~smit/asm01001.htm#ready (Assembly, segmentação de memória do MS-DOS, em inglês)
http://www.tecnobyte.com.br/sisnum1.htm (sistemas numéricos)
http://www.donnay-software.com/memory.htm#SymbolTable (Symbol table)
- Login ou registre-se para postar comentários
Anexo:
Programação de permissão de usuários no sistema em Clipper
Uma vez desenvolvi um método de senha para usuário. Cada usuário tinha acesso a determinada ação no sistema, dependendo do seu cargo na empresa. À pedidos, resolvi publicar o know-how.
Para que este esquema funcione, você tem que estar usando o método de compilação com .RMK e .LNK porque cada programa precisa ser uma função.
A idéia toda se baseia nas seguintes funções:
// atribuir permissões de usuários
SETKEY(-21, {|cPRO,nLIN,cVAR| MU_PER(cPRO,nLIN,cVAR) } ) // Ctrl+F2
// consultar permissões de usuário
FUNCTION PRG()
cSECAO := PROCNAME(1)
@ 24,69 SAY SPACE(10) COLOR "B/BG" // LINHA OPCIONAL
@ 24,79-(LEN(cSECAO)) SAY cSECAO COLOR "B/BG" // LINHA OPCIONAL
kIN := US->CARGO + cSECAO
AC->( DBSEEK(kIN) )
RETURN (cSECAO)
A outra função é a MU_PER() que, por ser um pouco grande, está sendo fornecida no final da página e não listada.
Observe que o campo US->CARGO deve estar no seu arquivo de usuários, assim que o usuário entra no seu sistema ele digita o seu nome de usuário e senha, daí ele posiciona o registro no usuário corrente.
Veja um exemplo de arquivo de "usuários" e um arquivo de "cargos", abaixo:
*** USUARIOS - ELENCO DOS USUARIOS DO SISTEMA
IF !FILE("USUARIOS.DBF")
aDBF := {}
aADD( aDBF, {"CODIGO", "C", 3, 0} ) // POSICAO 1 = CHAVE
aADD( aDBF, {"USUARIO", "C", 15,0} ) // POSICAO 2 = RETORNO
aADD( aDBF, {"NOME", "C", 35,0} )
aADD( aDBF, {"CARGO", "C", 3, 0} )
aADD( aDBF, {"IMPRESSORA","N", 2, 0} ) // IMPRESSORA Q ESTA USANDO
aADD( aDBF, {"SENHA", "C",10, 0} )
aADD( aDBF, {"SIGN", "N", 3, 0} )
aADD( aDBF, {"LAST_USER", "C", 3, 0} )
DBCREATE("USUARIOS", aDBF)
// ABRE DBF
USE USUARIOS ALIAS US EXCLUSIVE NEW
INDEX ON CODIGO TAG CODIGO TO USUARIOS
SET INDEX TO USUARIOS
// DEFINE USUARIO MESTRE = "SUPERVISOR"
US->( DBAPPEND())
US->USUARIO = "SUPERVISOR"
US->SENHA = CRIPT("1111111111", "USUARIOS")
TSTSENHA = CRIPT("1111111111", "USUARIOS")
TSTSENHA = DESCRIPT(US->SENHA, "USUARIOS")
US->CARGO = "001" // SUPERVISOR
ACESSO(US->CARGO, .T.) // ATRIBUI ACESSO TOTAL AO SISTEMA
IF !FILE("CARGOS.DBF")
aDBF := {}
aADD( aDBF, {"CODIGO", "C", 3,0} ) // POSICAO 1 = CHAVE
aADD( aDBF, {"CARGO", "C", 20,0} ) // POSICAO 2 = RETORNO -nome do cargo
aADD( aDBF, {"SIGN", "N", 3,0} )
aADD( aDBF, {"LAST_USER", "C", 3,0} )
DBCREATE("CARGOS", aDBF)
// ABRE DBF
USE CARGOS ALIAS CA EXCLUSIVE NEW
INDEX ON CODIGO TAG CODIGO TO CARGOS
SET INDEX TO CARGOS
CA->( DBAPPEND())
CA->CODIGO := "001"
CA->CARGO := "SUPERVISOR"
CA->( DBUNLOCK())
CA->( DBCOMMIT())
CA->( DBCLOSEAREA() )
ENDIF
ENDIF
A seguir a estrutura do arquivo que irá tratar as permissões dos usuários e irá trabalhar com a nossa função:
*** ACESSO - PERMISSAO DOS USUARIOS
IF !FILE("ACESSO.DBF")
aDBF := {}
aADD( aDBF, {"CODIGO", "C", 3,0} ) // CODIGO DO CARGO DO USUARIO
aADD( aDBF, {"SECAO", "C",10,0} ) // SECAO DO SISTEMA
aADD( aDBF, {"ACESSAR", "L", 1,0} )
aADD( aDBF, {"INSERIR", "L", 1,0} )
aADD( aDBF, {"ALTERAR", "L", 1,0} )
aADD( aDBF, {"EXCLUIR", "L", 1,0} )
aADD( aDBF, {"IMPRIMIR", "L", 1,0} )
aADD( aDBF, {"SIGN", "N", 3,0} )
aADD( aDBF, {"LAST_USER", "C", 3,0} )
DBCREATE("ACESSO", aDBF)
USE ACESSO ALIAS AC EXCLUSIVE NEW
INDEX ON CODIGO+SECAO TAG CODACE TO ACESSO
AC->( DBCLOSEAREA() )
ENDIF
Doravante, basta colocar a seguinte linha no início de cada programa:
pATUAL := PRG()
...e antes de qualquer ação do sistema, teste a permissão do usuário:
IF !AC->EXCLUIR //Testa se o usuário pode excluir o registro
MSGBOX1("Negado", "Permissão de Exclusão")
RETURN
ENDIF
Muito bem, agora você deve estar se perguntando: ...mas, como eu vou fazer para definir as permissões? Onde vou atribuir qual tipo de acesso cada usuário vai poder ter em cada programa???
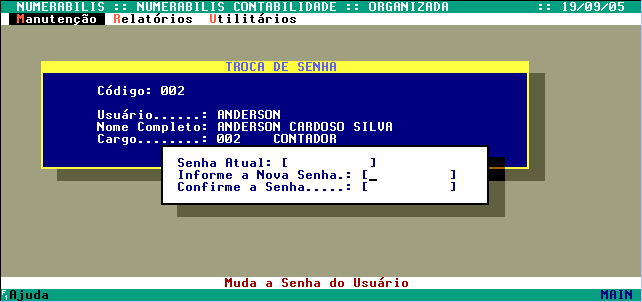
Bem, como já dito, só o supervisor poderá atribuir acessos ao sistema, então primeiro passo: o usuário SUPERVISOR entra e visita cada programa e tecla CTRL + F2, aí é aberta uma janela com todos os cargos e permissões para você definir.
Insira a linha a seguir no programa principal do seu sistema:
SETKEY(-21, {|cPRO,nLIN,cVAR| MU_PER(cPRO,nLIN,cVAR) } ) // Ctrl+F2
A função MU_PER() irá atribuir as permissões dos usuários.
A seguir, estou disponibilizando alguns fontes que usei no meu sistema de contabilidade que nunca terminei... hehehe. Só os fontes que interessa aqui, ok?! Estes fontes usam a VL2 (Visual Lib 2 -Disponível na página de Downloads).
Permissão de Usuários: Só informação:

Pressionando CTRL+F2 na manutenção de empresas, abre a janela de permissão de acesso dos usuários:

A coluna "grupo" fica congelada e as demais colunas "rolam" para esquerda e direita. Em nosso exemplo temos: Acessar, Inserir, Alterar, Excluir e Imprimir. Onde tem "ü" permite, onde tem "X" proíbe acesso.

Outras telas dos PRGs fornecidos, observe os nomes deles no canto inferior direito da tela.

Essas janelas a de cima e a de baixo foi feita com o TBrowse com a função NAVEGAR() que escrevi.

- Login ou registre-se para postar comentários
Índices CDX
MIGRAÇÃO DAS BASES DBFNTX PARA DBFCDX

Vantagens da base CDX:
✅ Índices com tamanho 70% menor em bytes;
✅ Arquivo do campo memo 30% menor em bytes;
✅ Velocidade na reindexação de 30-70% superior;
✅ Maior velocidade do sistema nas atividades relacionadas aos DBFs;
✅ Não há boatos sobre muitos problemas com índices (evita-se muitos transtornos como troca de informações pelo índice que quebrou e paradas na rede para reindexar o sistema).
Como fazer para usar os índices .CDX/.IDX ???
1º) No primeiro programa que abre algum DBF do seu sistema, acrescente estas linhas:
DBSETDRIVER("_DBFCDX") // Apenas no Clipper versão 5.3, acrescente esta linha.
2º) Depois anexe (linkedite) a lib DBFCDX.lib ao seu sistema (incluindo na lista de LIBs que o seu sistema utiliza).
Assim seu sistema já está preparado, sem embargo, haverá problemas de corrupção das bases que possuem campo memo, já que o driver CDX utiliza uma estrutura mais moderna para armazenar informações do campo memo e uma extensão diferente, a .FPT (ao invés de .DBT).
Como eu faço para transformar os .DBT para .FPT para que o sistema funcione?!?!?!
3º) Faça um BackUp (cópia de segurança) do diretório onde se encontram as bases de dados do seu sistema, caso necessite voltar o BackUp por algum motivo, apague primeiro todo o conteúdo do diretório atual das bases para que não haja confusão entre .DBF que chama .CDX/.IDX e .DBF que chama .DBT., pois ao descompactar/voltar o BackUp os arquivos que já existem serão ignorados.
4º) Preparei um utilitário para isso, rode o DBT2FPT.exe no diretório onde estão as bases de dados e este pequeno programa fará todo o trabalho para você! Para isso baixe o CDX_UTIL.zip onde você encontrará o DBT2FPT.prg e o FPT2DBT.prg (p/ inverso) e compile-o com o Clipper 5.2. Vide anexo.
A base de dados DBFCDX só está disponível a partir da versão 5.2 do Clipper! Portanto, se você utiliza a versão igual ou inferior à 5.1 veja as observações exaradas sobre Migração Clipper 5.1 p/ 5.2.
A diferença entre IDX e CDX é que o segundo é uma "bolsa" de índices, apenas.
Para confeccionar um programa flexível, você deve verificar a existência de um arquivo de índice com a função INDEXEXT(), que retorna o nome da extensão dos arquivos de índices.
Ex.:
IF !FILE( "CLIENTES.NTX" ) // NÃO RECOMENDADO! IF !FILE( "CLIENTES.NTX" ) // NÃO RECOMENDADO! IF !FILE( "CLIENTES"+INDEXEXT() ) // RECOMENDADO!
- Imagine o tempo que você teria poupado agora, hein?!
Tudo bem. E agora, como criar os índices?! Veja o exemplo:
IF !FILE( "AZIENDE"+INDEXEXT() )
IF SELECT("AZ") = 0 // Arquivo fechado
USE AZIENDE ALIAS AZ EXCLUSIVE NEW
ELSE
AZ->(DBCLOSEAREA()) // Fecha para abrir em modo "exclusive"
USE AZIENDE ALIAS AZ EXCLUSIVE NEW
ENDIF
USE AZIENDE ALIAS AZ EXCLUSIVE NEW
INDEX ON CODIGO TAG CODIGO TO AZIENDE
INDEX ON FANTASIA TAG FANTASIA TO AZIENDE
INDEX ON RSOCIAL TAG RSOCIAL TO AZIENDE
ENDIF
No exemplo acima, foi criado uma "bolsa" de índices, é como se fosse mais de um arquivo de índice junto em um só arquivo, identificados pelo parâmetro TAG.
Tudo bem. E agora, como alterar a ordem dos índices?! Veja o exemplo:
AZ->( ORDSETFOCUS("RSOCIAL") )
Ou
AZ->( ORDSETFOCUS(3) )
- Login ou registre-se para postar comentários